图像和谐化
图像和谐化图像和谐化论文整理DIH主要工作模型简介DoveNet主要工作模型简介
图像和谐化论文整理

DIH
【2017 CVPR】Deep Image Harmonization
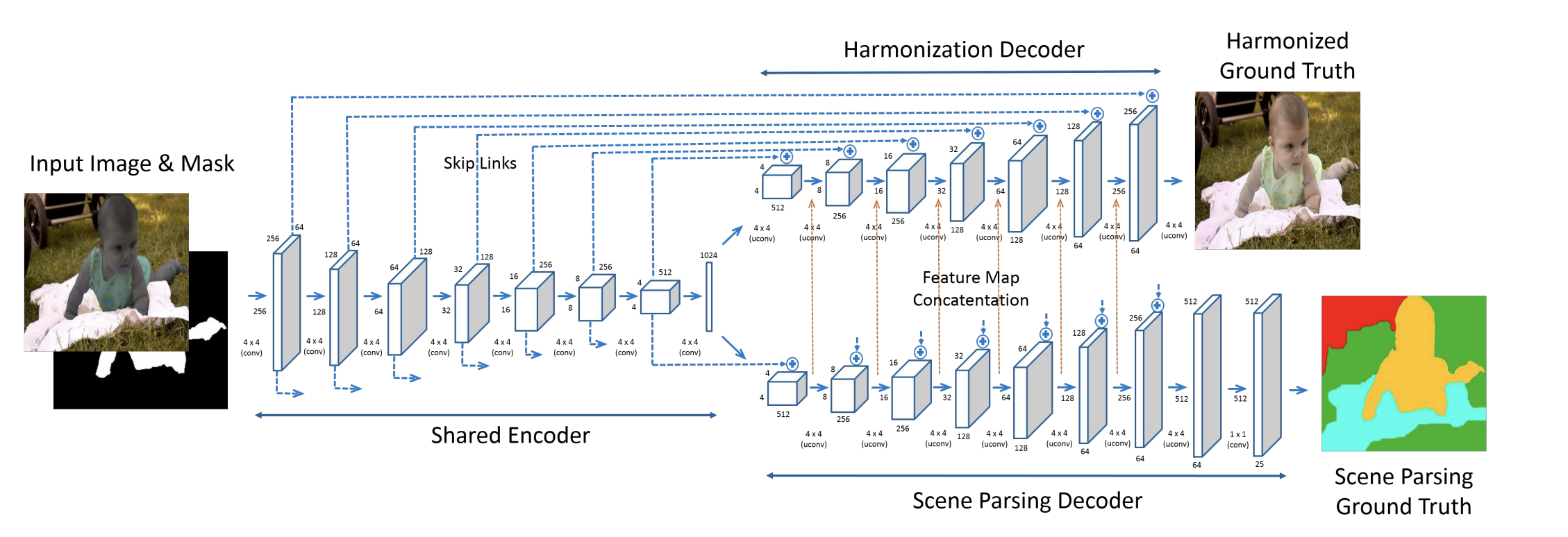
主要工作
- 第一次提出深度学习端到端的网络来解决和谐化问题
- 采用U-Net网络结构有效进行了和谐化以及语义分割的任务
- 提出了一套构建数据集的方式
模型简介
- 模型有一个Encoder用来提取图像特征,另有两个Decoder,一个用来生成和谐化图片,一个用来生成语义分割结果;语义分割Decoder的每一层传递给和谐化Decoder协助其完成和谐化
DoveNet
【2020 CVPR】DoveNet: Deep Image Harmonization via Domain Verification
主要工作
开放了一个大规模图像和谐化数据集iHarmony4,后续的研究工作基本都基于这个数据集进行训练和测试
Sub-dataset HCOCO HAdobe5k HFlickr Hday2night #Training 38545 19437 7449 311 #Test 4283 2160 828 133 提出用域验证的方式辅助和谐化任务
模型简介
- 利用一个U-Net结构的生成器
- 用全局判别器
- 用域验证判别器
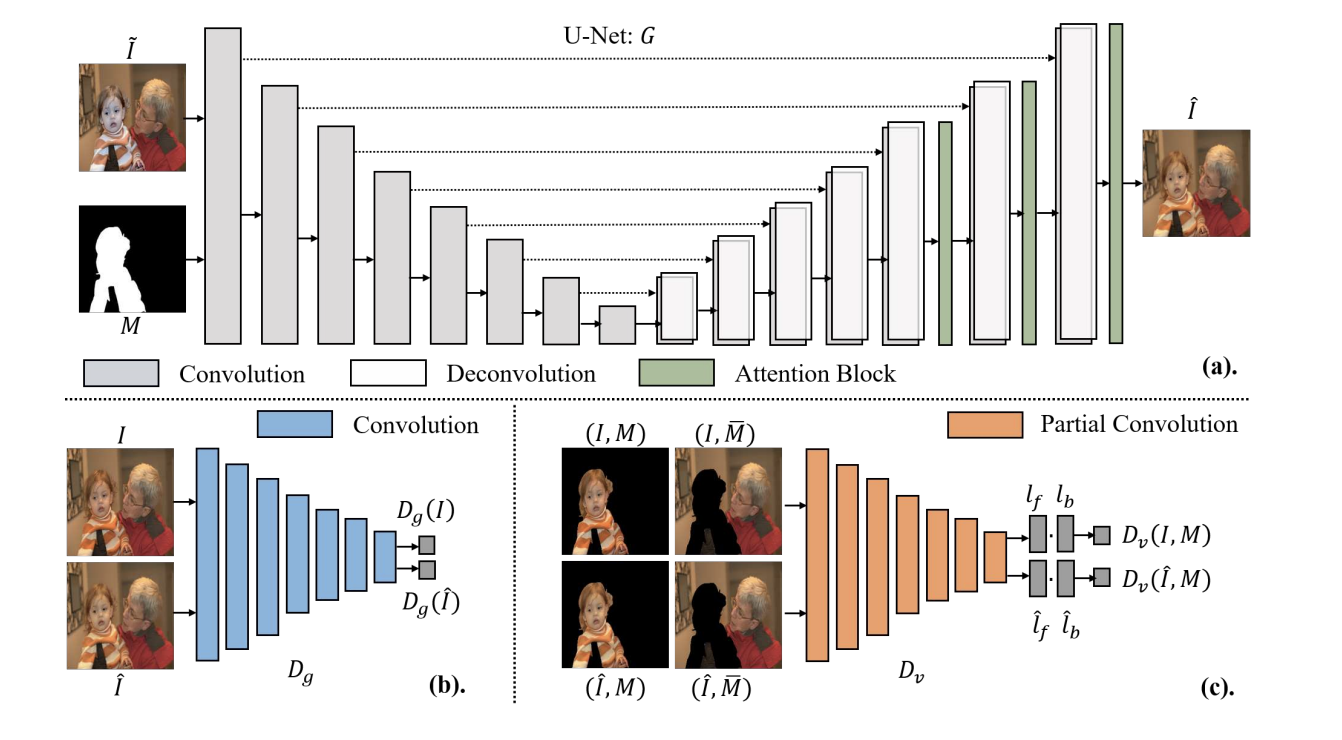
【2020 IEEE TIP】Improving the Harmony of the Composite Image by Spatial-Separated Attention Module
主要工作
- 卷积网络看到了全图,抽取的是全图的特征,在图像-图像的领域存在劣势。为了分别抽取前景、背景和混合特征,增加了注意力模块,基于给定的掩码来对这些不同区域分别提特征
- 因为图像只需要针对前景做变换,因此在输出层基于掩码,直接保留了背景不变(很多方法连同背景一起变化了,然后在测试阶段保持背景不变)
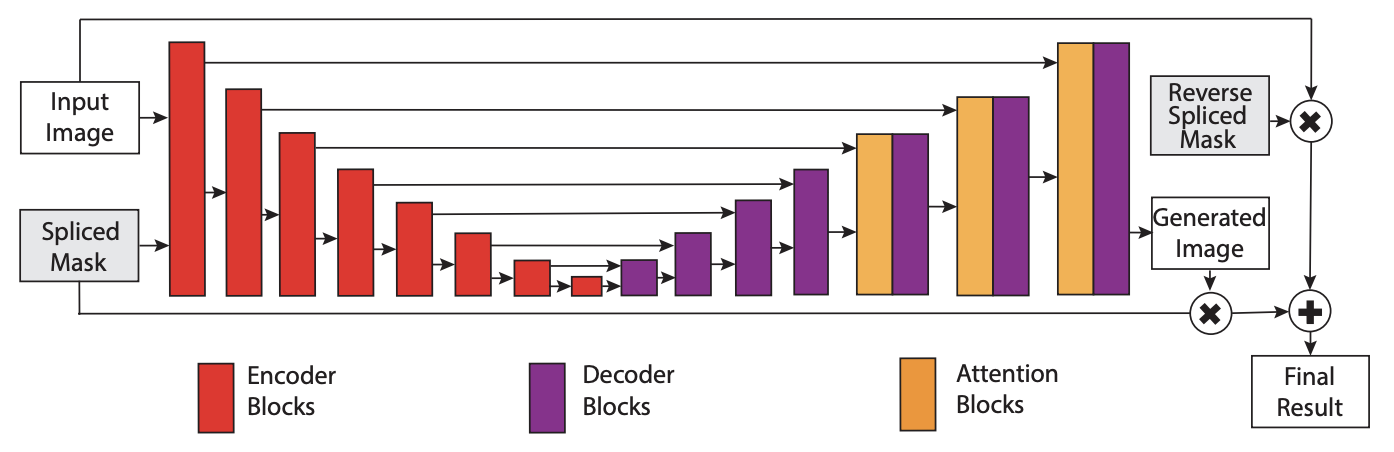
BargainNet
【2021 ICME】Bargainnet: Background-Guided Domain Translation for Image Harmonization
主要工作
之前的工作(DoveNet)太暴力,直接用一个U-Net生成图片,没有利用上背景对前景的关键指导信息
提出了域码提取器(domain code extractor)的概念,抽取背景的域特征然后辅助前景和谐化
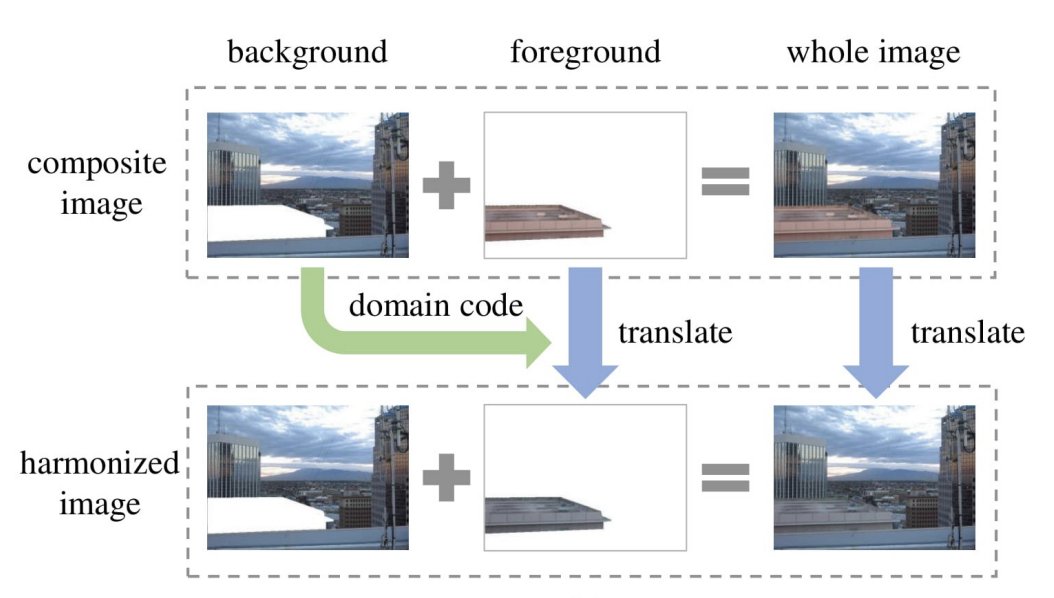
模型简介
- 模型看起来很复杂,但实际上除了左上角的Extractor以外,其它的Extractor只参与训练过程(用来计算Loss,训练Extractor使其能准确抽取域特征),不参与推理
- Extractor抽取背景的“域码”,结合合成图片放入生成器(U-Net类型)得到和谐化图片
- 为了训练Extractor,构建了几个额外Loss,分别是:原图的域码和和谐化后前景的域码应该接近;合成图片的前景域码应该与原图的前景域码有较大差异等
IntrinsicIH
【2021 CVPR】Intrinsic Image Harmonization
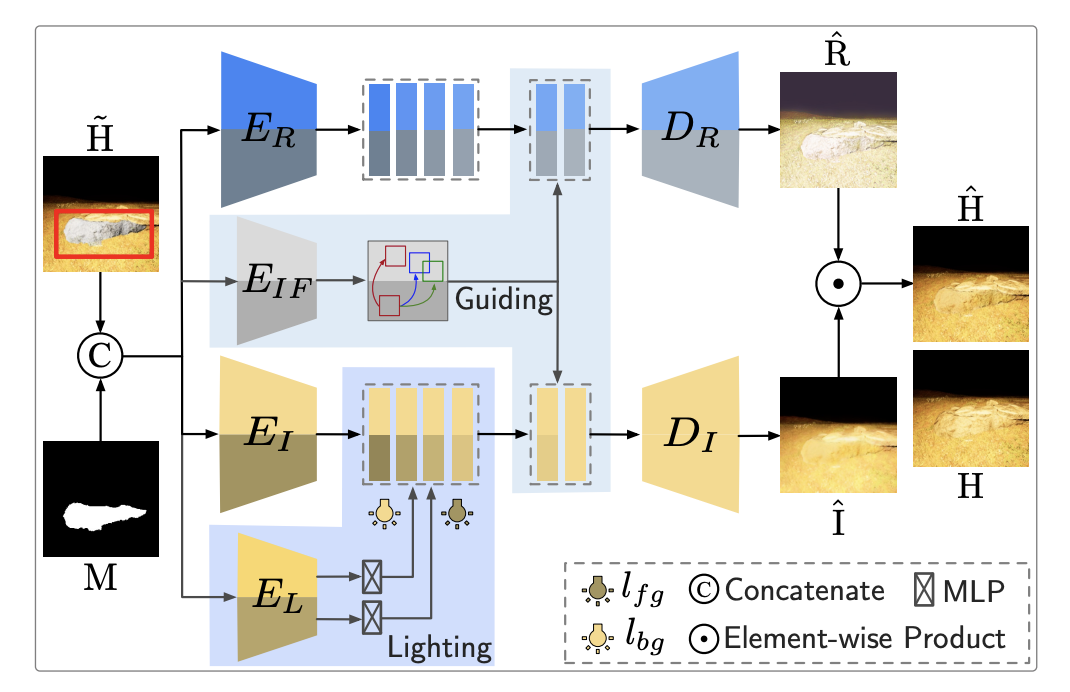
主要工作
- 依据光照理论,将图片划分为本征图和光照图。本征图是物体的固有属性,不随其所在空间光线的变化而变化;光照图是物体当前受光照影响的增益属性。本征图和光照图结合形成了肉眼看见的图
- 基于上面的理论,和谐化任务就转化成:从合成图片分离出本征图和光照图,然后使得本征图保持不变,修改光照图中的前景部分,使其和背景的光照匹配;最后结合本征图和修改后的光照图
模型结构
- 有两个Encoder-Decoder结构分别生成本征图和光照图
- 另有一个Encoder
- 一个Encoder
DHT
【2021 ICCV】Image Harmonization with Transformer
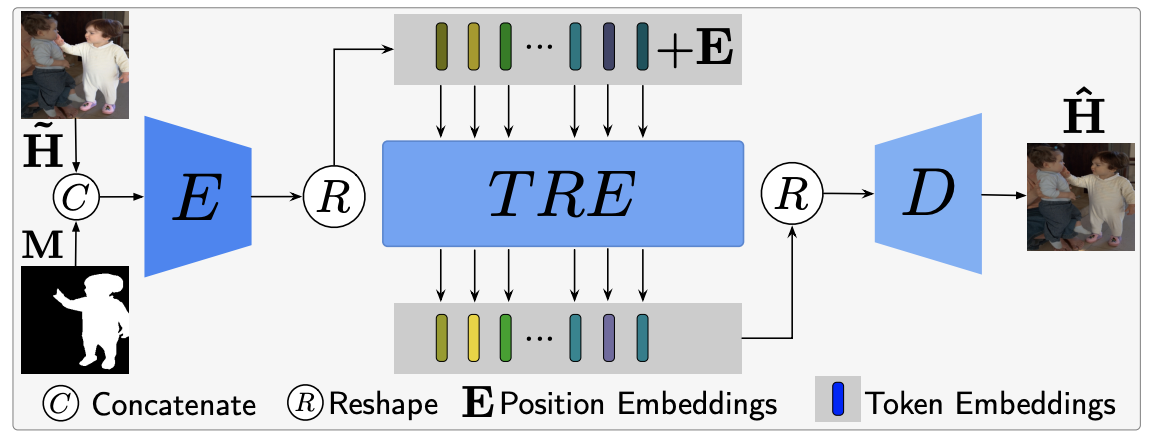
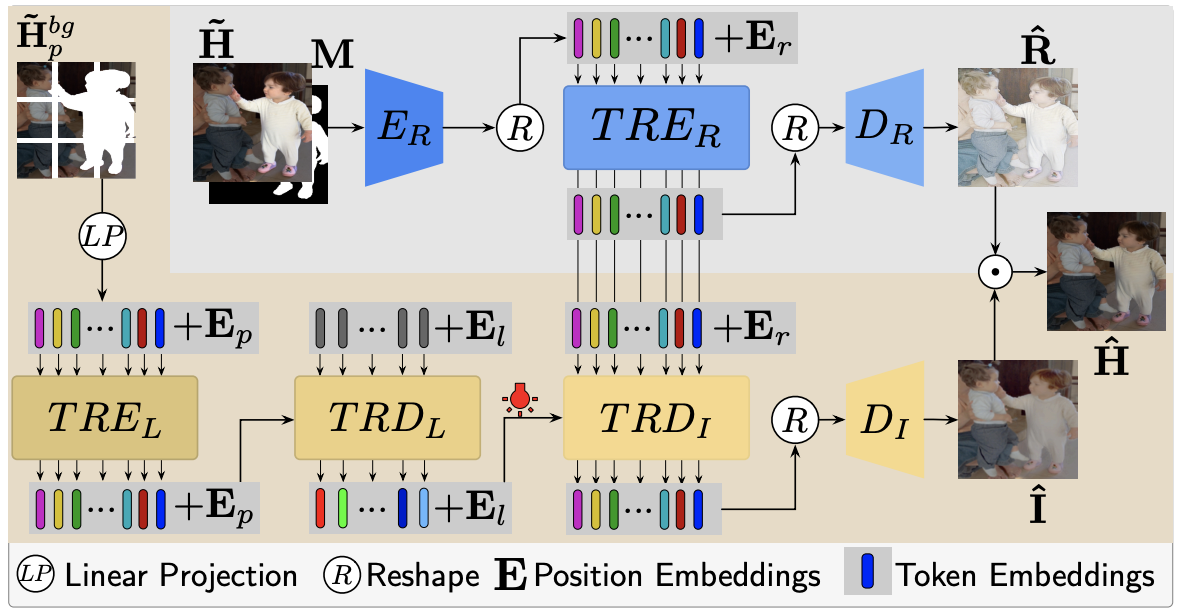
主要工作
- 设计了ViT的和谐化网络,包括一个基础的和一个复杂的模型
- 提出的模型在图像修复和图像增强两个任务中也有明显效果
模型结构
- 基础模型结构清晰,输入经过两层的卷积下采样后输入Transformer Encoder,然后再上采样还原得到和谐化图片
- 复杂模型沿用了IntrinsicIH的思路,将图片划分为本征图和光照图;本征图由基础模型得到,另有一个通道用来抽取背景域的光照特征,将抽到的特征和基础模型中的Encoder输出作CrossAttention得到和谐化的光照图;最后重新组合本征图和光照图得到和谐化图片
iDIH
【2021 WACV】Foreground-aware Semantic Representations for Image Harmonization
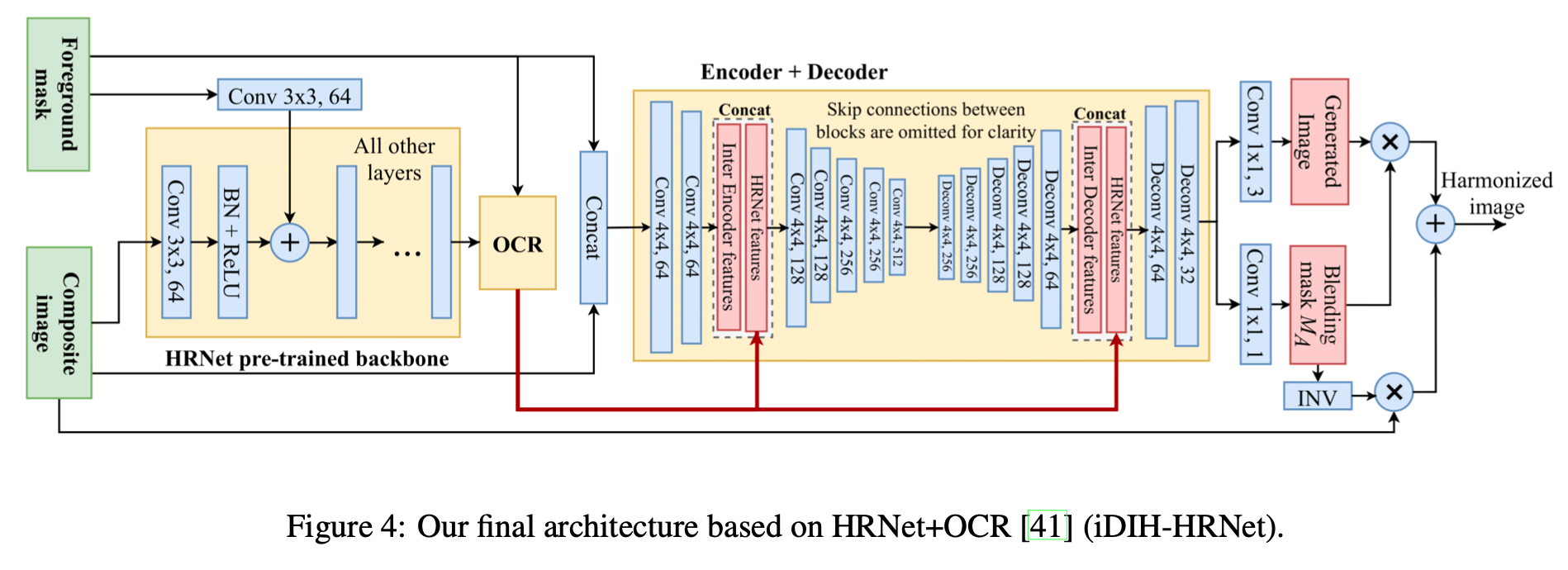
主要工作
- 利用基于ImageNet预训练出的模型(HRNet + OCR)做图像和谐化任务
- 经过HRNet抽取的高维特征,结合前景掩码生成注意力机制掩膜
- 一句话概括:将从预训练好的HRNet+OCR模型中抽取的图像高级语义特征放入编码解码器结构,解码器生成了Generated Image和Blending Mask

模型细节
预训练网络的输入是RGB三通道图片,但在和谐化任务中多了一个掩码通道。模型让掩码通道单独过一个卷积层变为64通道,然后再加入预训练网络中一起参与训练
经过预训练网络得到的高级图像表征,如何放入Encoder-Decoder模块中。模型让高级表征同时在Encoder和Decoder阶段Concat进去,感觉类似于残差连接的意思
Object-Contextual Representations对象上下文表征
- 针对语义分割问题(图像分割与图像和谐化都是高分辨率的图像生成问题,异曲同工,因此某种程度上具备参考价值)
- 像素本身不具有语义特征,所以考虑利用像素上下文区域的语义特征来增强像素表征
HRNet

- 主要研究输出高分辨率的图像表征(现有方法大多是从高分辨率产生低分辨率表征然后再恢复成高分辨率)
- 传统的卷积方法,基本是以一种串联的形式组织起网络(比较典型的U-Net,先卷积,然后反卷积还原)
- HRNet是将不同分辨率的feature map进行并联,在其基础上添加不同分辨率feature map之间的交互
- 达到语义分割领域的SoTA水平
RainNet
【2021 CVPR】Region-aware Adaptive Instance Normalization for Image Harmonization
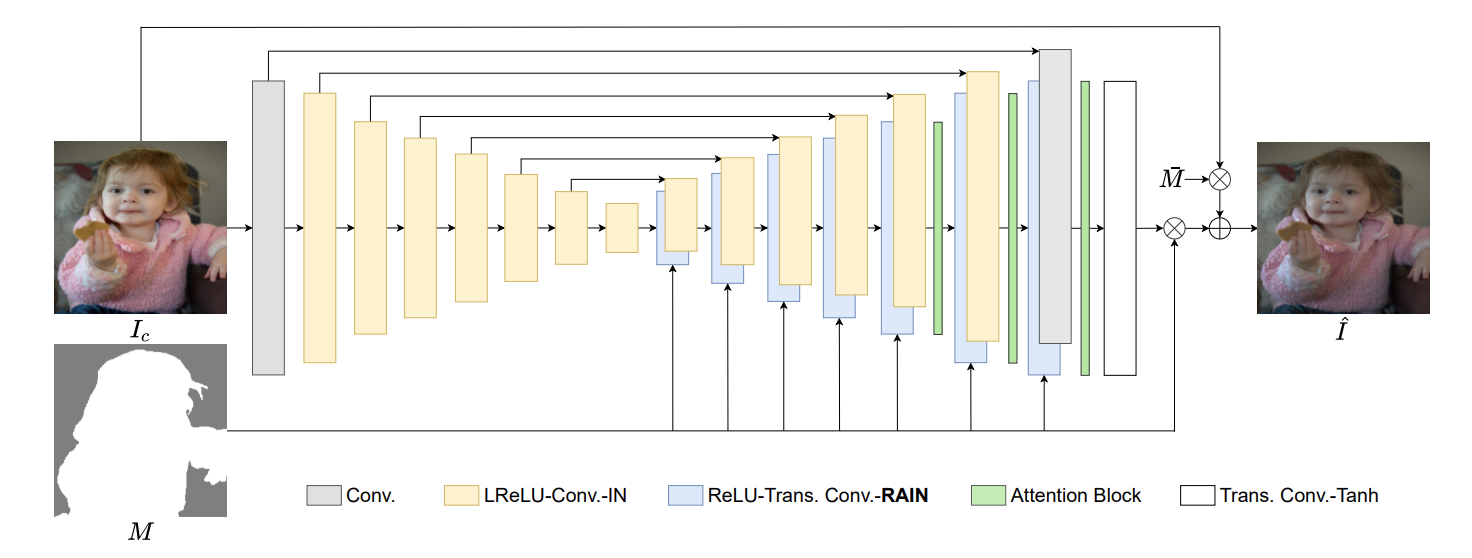
主要工作
将图像和谐化工作视作一种风格迁移问题来解决
提出了一种针对于图像和谐化任务的归一化算法,把这种算法应用到基础模型上(如U-Net)效果有提升
因为是一种通用的模块设计,即插即用
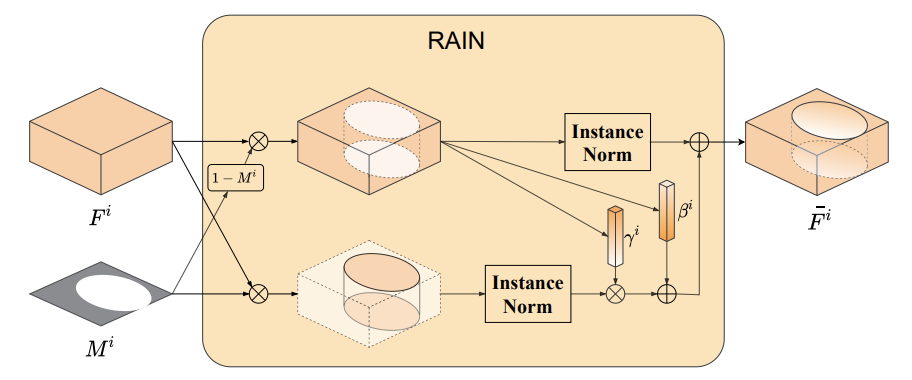
模型结构
- 同样使用了U-Net的网络结构,和其他任务不同的是,网络的输入没有同时包含前景掩码
- 前景掩码在Decoder阶段,在归一化层被引入,每次归一化都会用到前景掩码
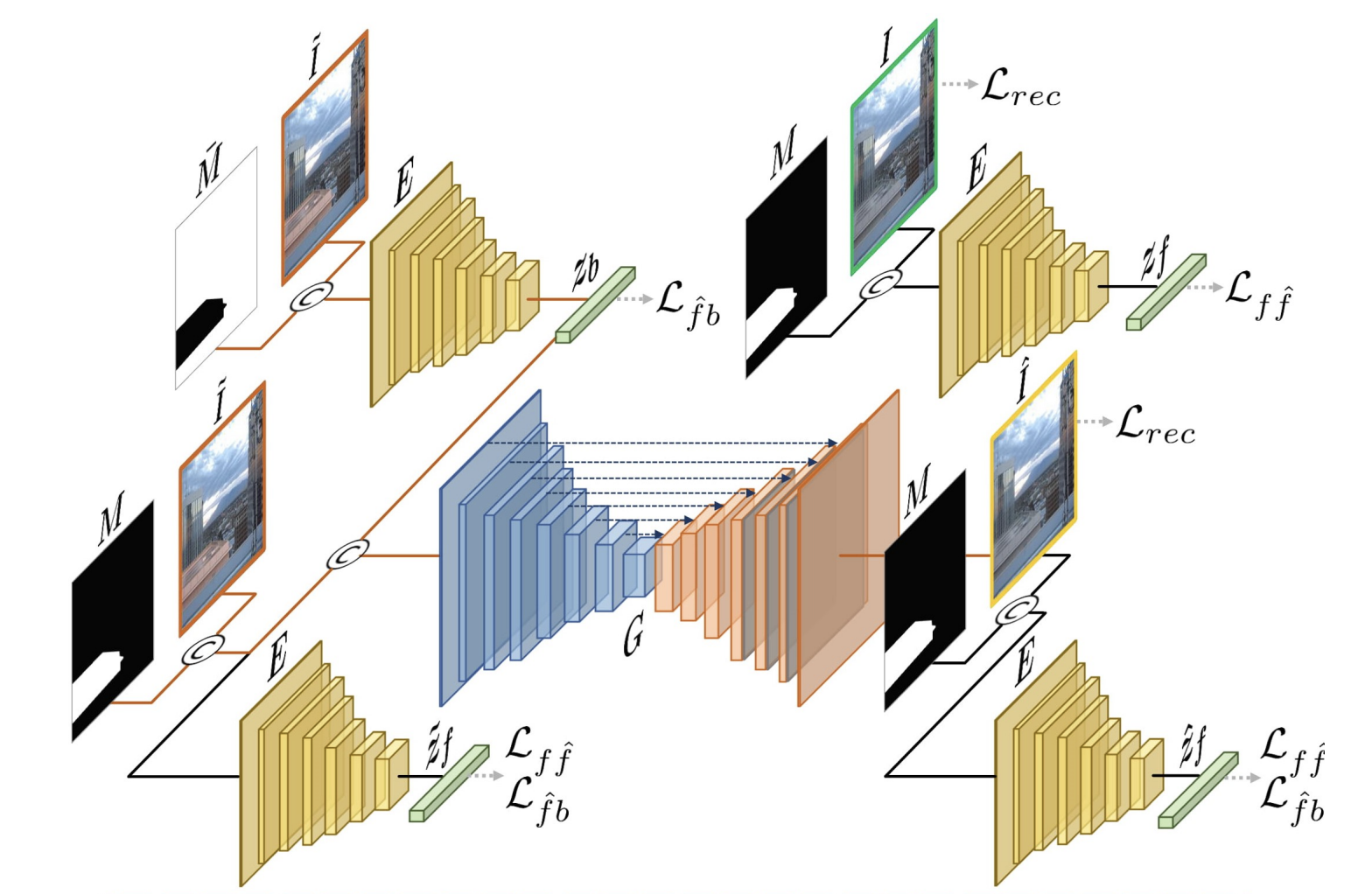
SSH
【2021 ICCV】SSH: A Self-Supervised Framework for Image Harmonization
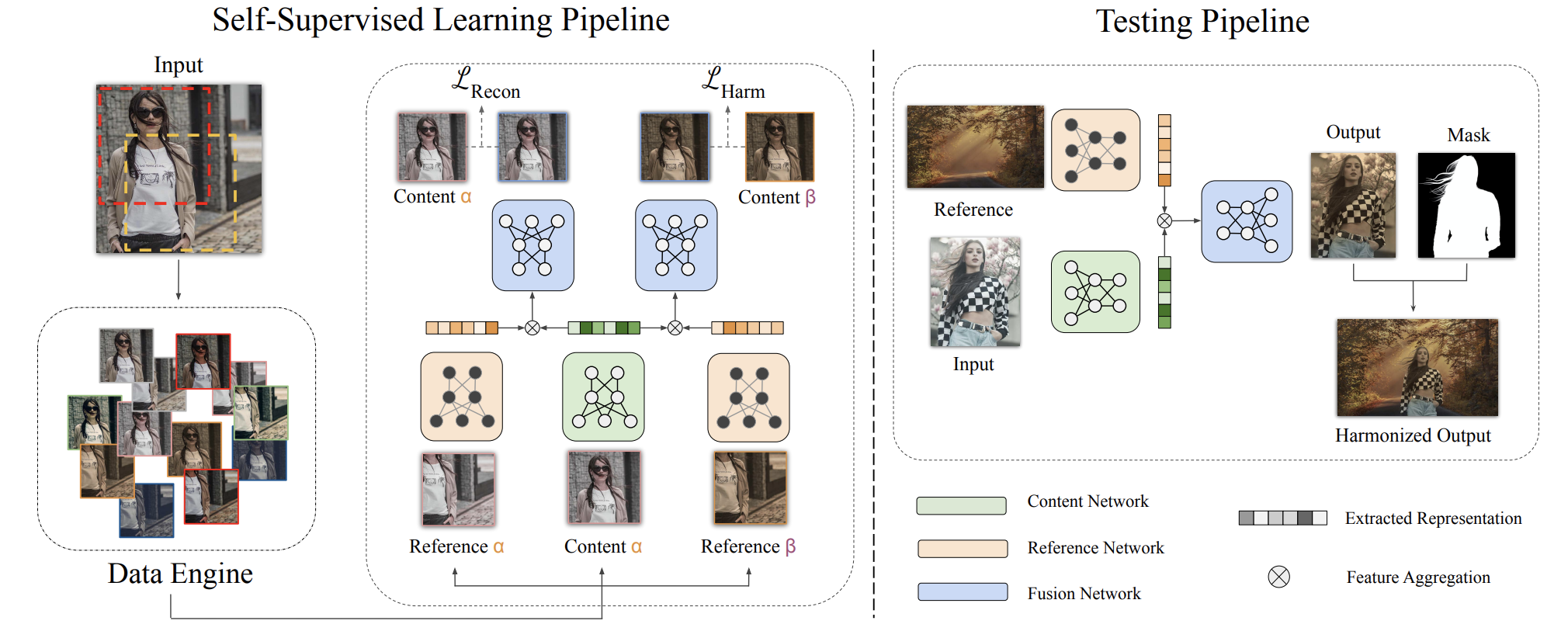
主要工作
采取自监督的方式进行训练,不需要人为的构造训练数据,消除了由数据规模带来的性能瓶颈
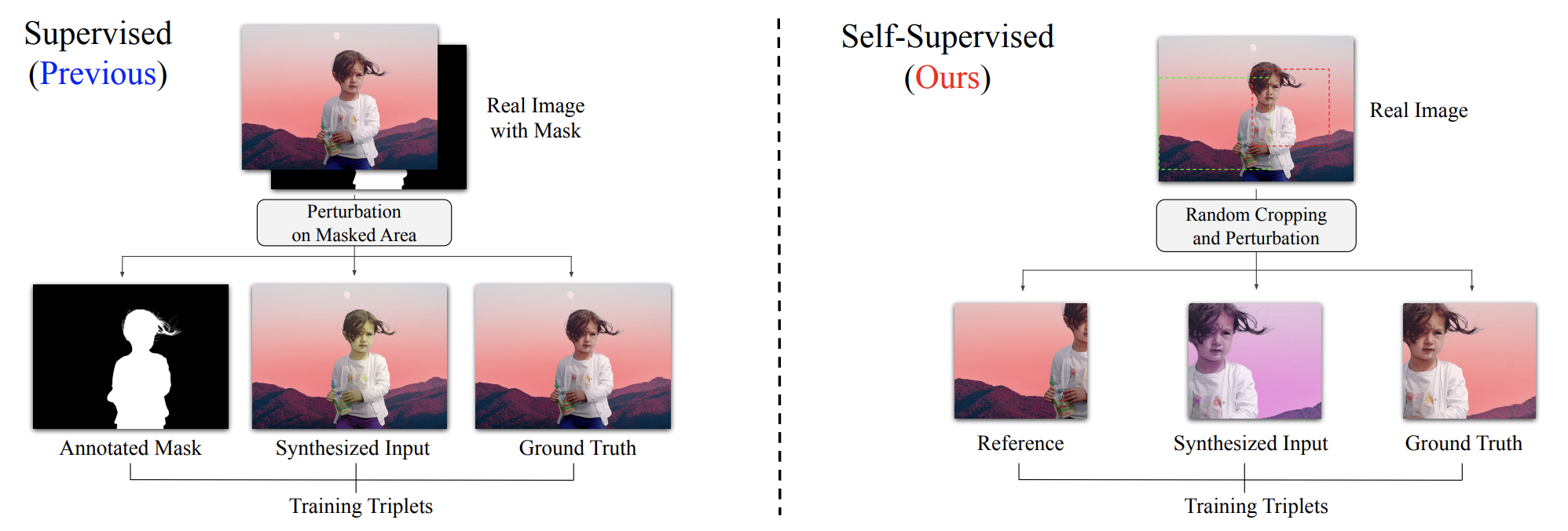
- 过去的数据集,是基于前景图像的掩码,构造合成图片,然后通过端到端的网络生成和谐化图片然后跟原图比较算loss
- 这种方式有效,但是数据集很难造,从数据的角度性能是存在瓶颈的
- 这种自监督的网络在训练阶段不需要掩码的参与,只需要一些真实的图片就可以
- 通过随机使用LUT对图片作处理,产生不同风格(色调)的图片,然后对真实图片和LUT图片作随机裁剪,然后基于真实图片的片段信息(色调信息)去还原LUT片段
- 这种手段就能避免制作大量的训练数据所需要的成本
图片预处理模块用来调整图片的色调
模型结构
- 第一步:给出一张真实图片,基于数据引擎(基于LUT的数据增强手段)将这张图片转换为多种不同风格的图片并切片
- 第二步:从数据引擎选取两种风格的图片切片各两张,称作
- 第三步:抽取
- 第四步:抽取
- 基于以上步骤就训练出了三个网络,分别是抽Reference特征的网络、抽Content特征的网络,以及一个图片生成网络
- 在测试阶段,我们将背景图片作为Reference,前景图片作为Content,放入网络,就能获得和谐化以后的前景图片,然后再利用掩码把需要的部分裁剪出来
SCS-Co
【2022 CVPR】SCS-Co: Self-Consistent Style Contrastive Learning for Image Harmonization
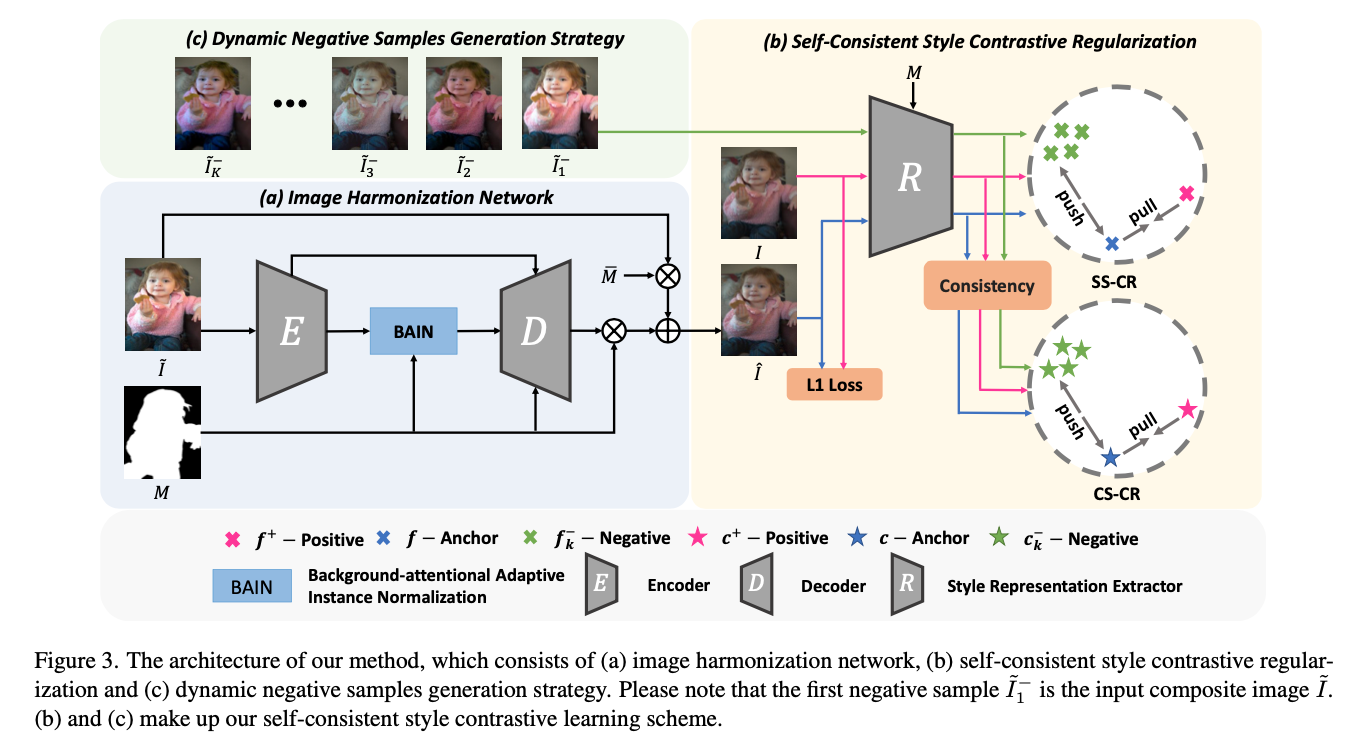
主要工作
- 将对比学习引入和谐化任务(传统的方法,将生成的图片和真实图片的距离作为loss,相当于真实图片是一个正例)
- 提出了一个正则化方式(Background-attentional adaptive instance normalization,BAIN),用来学习(检测)前景-背景中相似实体的特征,作有针对性的和谐化
模型结构
- 首先仍然是一个Encoder-Decoder结构的生成器,这个结构和RainNet非常类似,也是只把合成图片输入Encoder,然后构造了一个正则化层,在这一层引入掩码
- 设计了一个动态负例生成器
- 风格对比模块(分为两个部分,一个是self-style,用于判断前景风格拟合的效果,意图让生成的前景和ground-truth尽可能接近,而让负例的前景和ground-truth疏远;另一个是consistent-style,用于判断前景和背景之间的风格差异,意图让生成的前景和ground-truth的背景风格尽可能接近,而让负例的前景和ground-truth背景尽可能远离
模型性能比较
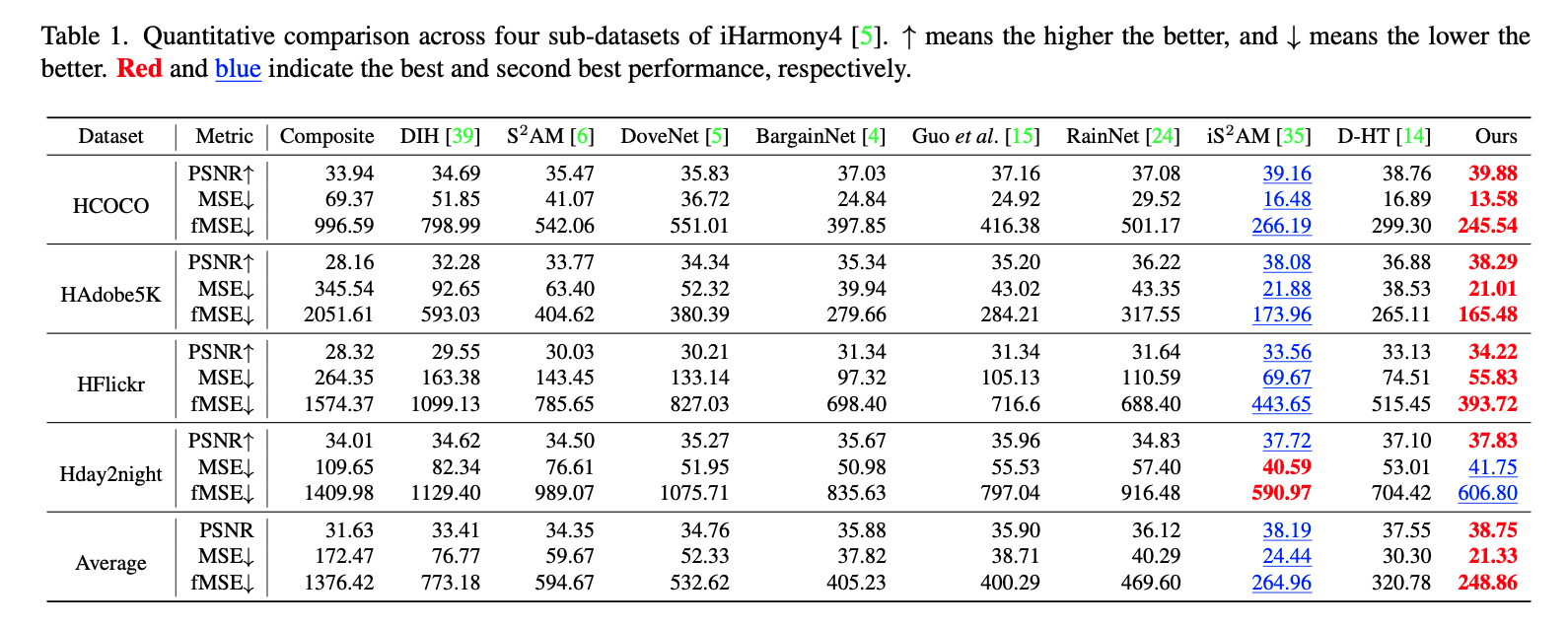
上表是2022年的论文SCS-Co中的指标表,SCS-Co和
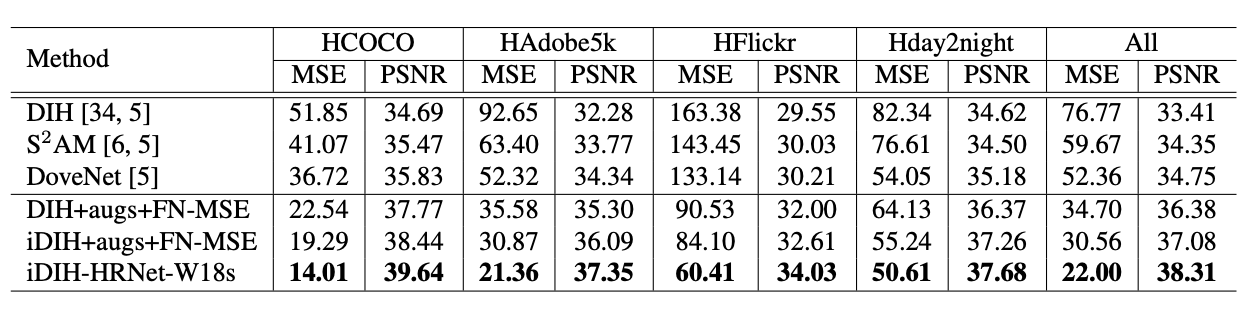
其它有意思的论文
CLIPstyler
【2022 CVPR】CLIPstyler: Image Style Transfer with a Single Text Condition
用CLIP提取文本信息对图像做风格迁移

当前工作的分析
目前的工作基于上面的论文之一:DHT。考虑在DHT的基础上,引入图像的高级表征(CLIP预训练模型提取的图像特征),希望能提高指标。这个思路和论文 iDIH 很类似,都是考虑加入预训练模型以提升质量,而iDIH 模型确实取得了非常好的结果(目前和SoTA几乎没有差距)
目前的困境在于:
DHT这个模型和当前的SoTA模型有距离(在小规模数据集上,ViT的效果是否与CNN有差距)
加入CLIP的可解释性不足。可以将CLIP提取的特征放进网络参与训练,但是即使性能有了微弱的提升,该如何解释CLIP为模型带来提升的原因呢?
在 iDIH 这篇论文中,也用到了预训练模型,他们的预训练模型起初是针对语义分割任务的,这个与训练模型起初就是针对从图像-图像的任务的。另一方面,它们利用抽取到的特征,对掩码做了语义上的增强,从这个角度他们可以说我们抽到的特征是有价值的,有很大作用的
目前是用CLIP从图像中抽取特征,可解释性不足。如果换成基于文本的特征,比如:把前景调亮一点、调暗一点。如果这样做的话,可解释性就有了,相当于用文本信息去指导图像做和谐化,这就成为了一个标准的多模态任务。这样做可能会出现几个潜在的难题:
- 需要标注训练的文本数据,需要定义标注规范,实际上这种规范可能很难制定(可以说调亮一点,调暗一点,但是调亮或调暗多少呢?本质上还是需要Ground-Truth去指导,也就是说这种文本信息提供的消息是很有限的)
- 假设已经有了训练的数据,以当前设计的模型进行训练,效果可能仍然没有提升,此时做消融实验可能会发现有没有CLIP模块效果是一样的
下一步的工作
- 目前CLIP预训练模型抽取的特征放在HT这个基础模型上,性能有提升,考虑进一步训练看看有没有更大提升
全量数据IHarmony Dataset(IHD)训练 60epoch 结果 HT(Prev) DHT(Prev) MMHT Mask Embedding MMHT fg clip cross HT fg clip cross Parameters 4.773M 21.772M 21.800M 175.567M 160.241M Dataset: MSE | fMSE IHD: 37.07 | 395.66
Adobe: 47.96 | 321.14
COCO: 20.99 | 377.11
Flickr: 88.41 | 617.26IHD: 30.30 | 320.78
Adobe: 38.53 | 265.11
COCO: 16.89 | 299.30
Flickr: 74.51 | 515.45IHD: 31.06 | 350.29
Adobe: 41.46 | 320.34
COCO: 17.67 | 323.56IHD: 71.61 | 466.31
Adobe: 95.82 | 423.23
COCO: 39.60 | 403.28
Flickr: 166.15 | 850.29IHD: 37.65 | 403.87
Adobe: 47.68 | 342.83
COCO: 20.86 | 376.36
Flickr: 93.21 | 646.90
----- add comp image -----
IHD: 34.78 | 383.99
Adobe: 41.47 | 301.29
COCO: 20.15 | 367.36
Flickr: 86.48 | 605.25在iDIH论文中用的预训练模型是HRNet+OCR,考虑同样将这个预训练模型以同样的形式放进HT模型,看看性能有没有提升
可不可以考虑采取自监督的方式进行训练,这样的好处是:
- 打破了数据集规模对性能的限制,通过自监督的方式,理论上只需要大量的图片,就可以做和谐化任务
- 不需要基于iHarmony数据集做测试(避免和别的模型的直接比较,或者说可以把他们的模型迁移到我们的数据集上进行比较)
和谐化任务综述(总结)
图像和谐化任务汇总
图像和谐化是图像编辑领域的一项重要工作。在图像合成问题中,我们可能需要将前景图片拼接到背景图中,而由于前景和背景图片拍摄所处的环境、光照、气候等条件不同,将前景生硬地放到背景图上会出现视觉不协调的问题,即图片看起来是明显不真实的。图像和谐化的目标,就是解决图像合成问题中前景(Fore-ground)和背景(Background)的视觉一致性(visual consistency)问题,使得前景和背景组合得更加协调。
数据集
数据集的构建是图像和谐化任务中的一大难点。当前的深度学习方法极度依赖大规模的数据集,数据集的规模对模型的性能起到了至关重要的作用。而在图像和谐化任务中,我们可以很容易构建出各种各样的合成图片(只需要将前景放到背景上即可),但是我们需要专业人员耗费大量的时间和精力手动地将每一张合成图片进行和谐化,这使得构建非常大规模数据集的期望变得不现实。
为了解决这一问题,研究人员提出了一种替代的解决方案 [3]:将真实的图片视作和谐化以后的结果(Ground-Truth),裁剪出图片中的一个区域(基于语义的裁剪),对这个区域做风格的变换使其与原图的风格不一致,这就得到了人为构造的一张合成图片,并构造出了合成图片-前景掩码-真实图片对。我们可以在不耗费大量人力和时间成本的情况下构造出一定规模的数据集,然后基于这些数据训练深度学习模型,使模型能够处理和谐化任务。Cong, etc [2] 提出的iHarmony4数据集目前已被广泛应用在图像和谐化任务的训练和测试中,数据集包含了四个子数据集,分别是Microsoft COCO(HCOCO)数据集、MIT-Adobe5k(HAdobe5k)数据集、自行收集的Flickr(HFlickr)数据集,以及day2night(Hday2night)数据集。数据集的规模如下图所示:
| Sub-dataset | HCOCO | HAdobe5k | HFlickr | Hday2night |
|---|---|---|---|---|
| #Training | 38545 | 19437 | 7449 | 311 |
| #Test | 4283 | 2160 | 828 | 133 |
然而,上文所述的数据集构建方式仍然是存在问题的。在Jiang, etc [4] 的工作中提出了几点问题:
- 数据集的数量仍然是受限的,而且数据集需要提供精准的前景掩码才可以
- 背景遮挡问题:当前景占据了很大的比重时,和谐化的效果会显著降低
- 和谐化的多样性受限:真实场景下的和谐化,图片来源以及要做的和谐化的变换是各种各样的。但是如果手动去构造合成图片,那么这种多样性是不充分的
如何用自监督的方法构建出和谐化任务呢?[4]
给定任意一张图片,通过一种数据引擎将这张图片变换成各种各样的风格(保持内容不变),然后取两种不同风格
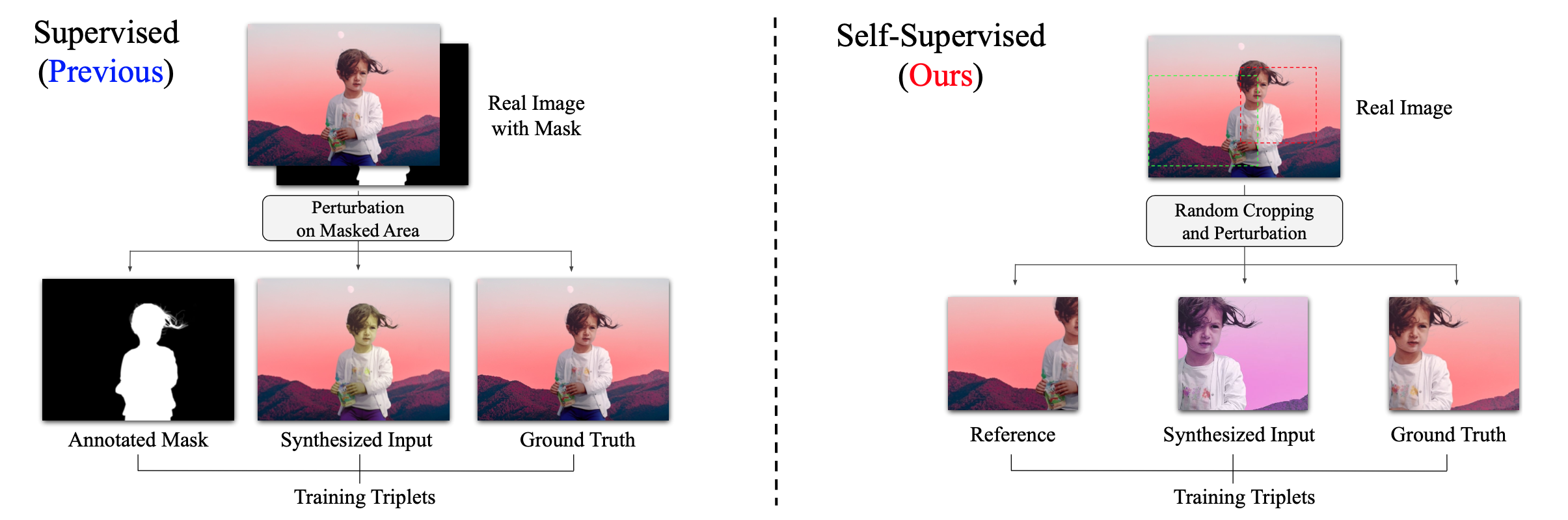
通过这样的方式,就不需要合成图片-真实图片对了,只需要真实图片就可以直接做和谐化任务,从数据规模的角度直接打破模型的性能瓶颈
评估指标
现有工作的量化评估主要是基于均方误差(Mean-Squared Errors, MSE)、前景均方误差(fMSE)、峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似度(Structural SIMilarity,SSIM)以及L1 norm
相关领域
图像和谐化
在深度学习兴起以前,多数的图像和谐化工作是基于图像的低级表征,如色彩分布,进行调整 [5, 6, 7](此处要补充)
Tsai, etc [3] 提出了第一个用于图像和谐化任务的端到端的基于学习的方法的卷积网络模型。这个基于U-Net网络结构的模型有效捕捉了图像的语义信息,并可以同时针对图像和谐化任务和语义分割任务进行训练。
图像-图像变换
此前工作
参考文献
[1] Niu, L., Cong, W., Liu, L., Hong, Y., Zhang, B., Liang, J. and Zhang, L., 2021. Making images real again: A comprehensive survey on deep image composition. arXiv preprint arXiv:2106.14490.
[2] Cong, W., Zhang, J., Niu, L., Liu, L., Ling, Z., Li, W. and Zhang, L., 2020. Dovenet: Deep image harmonization via domain verification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8394-8403).
[3] Tsai, Y.H., Shen, X., Lin, Z., Sunkavalli, K., Lu, X. and Yang, M.H., 2017. Deep image harmonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3789-3797).
[4] Jiang, Y., Zhang, H., Zhang, J., Wang, Y., Lin, Z., Sunkavalli, K., Chen, S., Amirghodsi, S., Kong, S. and Wang, Z., 2021. Ssh: A self-supervised framework for image harmonization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4832-4841).
[5] Cohen-Or, D., Sorkine, O., Gal, R., Leyvand, T. and Xu, Y.Q., 2006. Color harmonization. In ACM SIGGRAPH 2006 Papers (pp. 624-630).
[6] Jia, J., Sun, J., Tang, C.K. and Shum, H.Y., 2006. Drag-and-drop pasting. ACM Transactions on graphics (TOG), 25(3), pp.631-637.
[7] Pitie, F., Kokaram, A.C. and Dahyot, R., 2005, October. N-dimensional probability density function transfer and its application to color transfer. In Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1 (Vol. 2, pp. 1434-1439). IEEE.
[8] Zhu, J.Y., Krahenbuhl, P., Shechtman, E. and Efros, A.A., 2015. Learning a discriminative model for the perception of realism in composite images. In Proceedings of the IEEE International Conference on Computer Vision (pp. 3943-3951).
[9] Xue, S., Agarwala, A., Dorsey, J. and Rushmeier, H., 2012. Understanding and improving the realism of image composites. ACM Transactions on graphics (TOG), 31(4), pp.1-10.
[10] Ronneberger, O., Fischer, P. and Brox, T., 2015, October. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention (pp. 234-241). Springer, Cham.